Why the way text is split into tokens defines what an AI can understand, generate, and even “feel” like.
🚀 Introduction — The Hidden Layer of Language
When you interact with an AI model, you’re not talking to it in words — you’re talking to it in tokens.
Every piece of text, from a single letter to an emoji or an entire phrase, is split into small chunks called tokens.
The model doesn’t “see” sentences; it sees token sequences.
That invisible translation layer, known as tokenization, profoundly influences how efficiently and intelligently a Small Language Model behaves.
Tokens are the building blocks of text representation in language models.
They are numerical encodings of linguistic units — roughly equivalent to subwords.
Example:
Sentence: "NanoLanguageModels.com is awesome!"
Tokens: ["Nano", "Language", "Models", ".", "com", " is", " awesome", "!"]
Each token maps to an integer ID, stored in a vocabulary.
The model learns relationships between token IDs, not between words directly.
To understand how a model “thinks,” you must understand what it considers a token.
⚙️ Step 2: Tokenization Algorithms — The Three Main Approaches
| Method | Description | Example Use |
|---|---|---|
| WordPiece | Breaks words into subwords using frequency statistics | BERT, Gemma |
| Byte Pair Encoding (BPE) | Merges common byte pairs into tokens | GPT-2, TinyLlama |
| SentencePiece / Unigram | Probabilistic token segmentation without spaces | Phi-3, Mistral |
Example:
| Text | WordPiece | BPE | Unigram |
|---|---|---|---|
| “tokenization” | token ##ization | token iz ation | tok en iz ation |
Each method encodes text differently — and that difference directly affects model size, efficiency, and interpretability.
🧩 Step 3: Why Tokenization Matters More for Small Models
Small models (1–7B parameters) have limited capacity — fewer neurons to store and generalize language patterns.
That means every tokenization choice counts.
Impact Areas:
- Vocabulary Size — smaller vocab = less memory, faster inference
- Context Efficiency — shorter token sequences = fewer steps per prompt
- Generalization — well-designed tokens preserve meaning with fewer splits
If a model splits words awkwardly (e.g., “multi” + “media” + “tion” + “al”), it struggles to infer context naturally.
So, a well-optimized tokenizer can make a small model “feel” smarter than it is.
⚡ Step 4: Token Economy — The Context Window Effect
Context windows (e.g., 2K, 4K, 8K tokens) are token-limited, not word-limited.
Example:
- A 4K-token model ≈ ~2,500–3,000 English words
- But far fewer in languages like Chinese or Arabic (denser tokens)
If your tokenizer is inefficient, you “waste” context space on redundant or fragmented tokens.
That’s why companies like OpenAI, Mistral, and Google invest heavily in tokenizer design.
🧮 Step 5: Tokenization and Model “Personality”
A model’s token vocabulary subtly defines how it expresses itself.
Certain tokens represent emotional or stylistic expressions better than others.
Example:
| Model | Token Style | Tone |
|---|---|---|
| TinyLlama | BPE | direct, compact, technical |
| Phi-3 Mini | Unigram | conversational, smooth |
| Gemma 2B | WordPiece | balanced, structured |
| Mistral 7B | BPE | fluent, expressive |
The tokenizer defines the rhythm of how a model “talks.”
In this sense, tokenization gives a model its linguistic fingerprint — shaping tone, flow, and even “vibe.”
⚙️ Step 6: Example — Visualizing Token Splits
Let’s test how different tokenizers break the same text:
from transformers import AutoTokenizer
models = [
"TinyLlama/TinyLlama-1.1B-Chat-v1.0",
"microsoft/Phi-3-mini-4k-instruct",
"google/gemma-2b",
"mistralai/Mistral-7B-Instruct-v0.2"
]
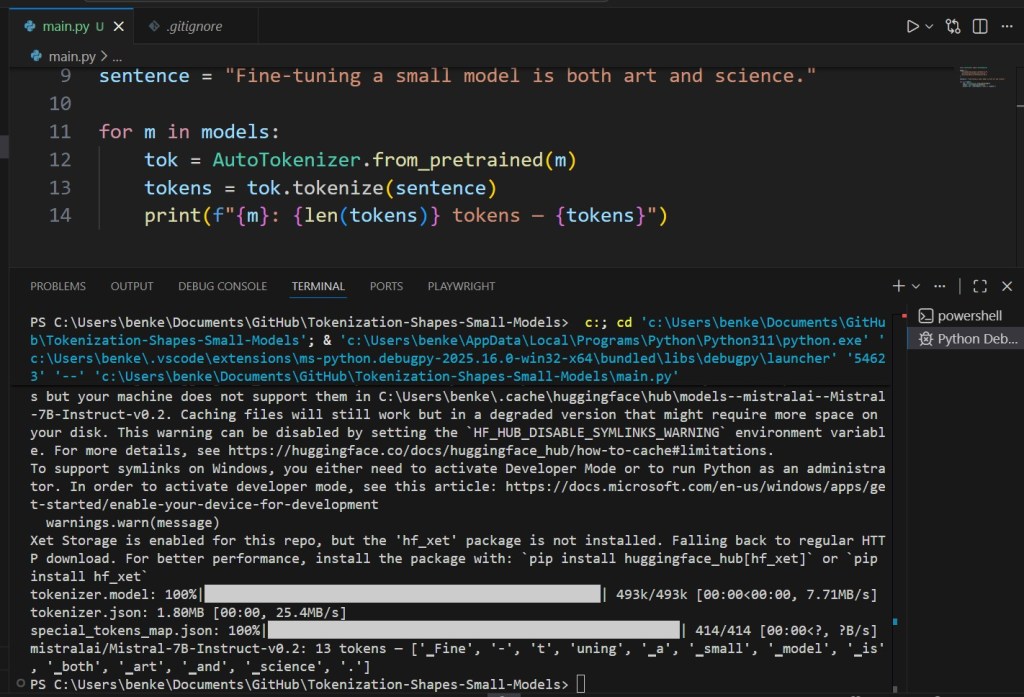
sentence = "Fine-tuning a small model is both art and science."
for m in models:
tok = AutoTokenizer.from_pretrained(m)
tokens = tok.tokenize(sentence)
print(f"{m}: {len(tokens)} tokens — {tokens}")
Python code available on Github here.
You’ll see huge differences — some split “fine-tuning” into one token, others into three.
That affects both efficiency and the nuance of how “fine-tuning” is understood.
🧩 Step 7: Token Efficiency Benchmarks
| Model | Tokenizer | Avg Tokens per 100 Words | Speed | Memory |
|---|---|---|---|---|
| TinyLlama | BPE | 118 | Fastest | Low |
| Phi-3 Mini | Unigram | 104 | Medium | Low |
| Gemma 2B | WordPiece | 121 | Medium | Medium |
| Mistral 7B | BPE | 110 | Balanced | High |
The most efficient tokenizer isn’t always the smallest — it’s the one that fits the model’s internal representation best.
⚙️ Step 8: Custom Tokenizers for Private Models
If you fine-tune your own SLM, consider building a domain-specific tokenizer — especially for jargon-heavy text (finance, law, healthcare).
Example using Hugging Face’s tokenizers library:
from tokenizers import ByteLevelBPETokenizer
tokenizer = ByteLevelBPETokenizer()
tokenizer.train(["data/corpus.txt"], vocab_size=20000, min_frequency=2)
tokenizer.save_model("custom_tokenizer/")
Benefits:
- Reduces token count per document
- Improves task accuracy
- Speeds up fine-tuning
🧠 Step 9: Tokenization and Multilingual Models
Small multilingual models face a tradeoff:
- Large vocabularies improve coverage
- But reduce per-language depth
Some modern tokenizers (like Google’s SentencePiece) solve this by using byte-level tokens, which are universal across languages.
A byte-level tokenizer gives an SLM global reach with local precision.
🔮 Step 10: The Future — Tokenless Models
Researchers are exploring character-level and token-free models that process text continuously without discrete token breaks.
This could:
- Eliminate token inefficiencies
- Handle arbitrary languages and symbols
- Enable smoother reasoning across formats
Projects like Charformer, Retokenizer, and ByT5 are early steps in this direction.
In the long run, tokenization may disappear — but for now, it’s still the DNA of every model.
